
- AIモデルの性能というと、まずベンチマークのスコアが話題になる
- ただ、最新のベンチマークが測るのは、数学オリンピック級の難問や博士級の専門知識、競技プログラミングといった「最上位層の能力」であることが多い
- そうしたスコアは研究者やトップクラスのエンジニアには重要でも、一般のユーザーの日常用途で本当に有効かは別の話
- 私たちが日常でAIに投げるのは、動くコードを書く・レビューする・小さな事業の相談に乗るといった現場的な仕事
- そこで効くのは難問を解く力より、読みやすさ・誤検知の少なさ・現実的な判断力
- 「ベンチマーク上位のモデルが普段使いでも最適とは限らないのでは」と考え、自分で確かめてみた
- 比較対象はGPT-5.5 Thinking(通常/拡張)、Claude Sonnet 4.6、Claude Opus 4.8、Claude Fable 5の計8構成
- この記事を読めば、「実装はどれ」「レビューはどれ」「事業相談はどれ」という実務目線の使い分けがわかる
この記事の前提と検証方法
こんな人に向けた記事
- 複数のAIを契約していて、どう使い分けるか決めかねている人
- ベンチマークの比較記事を読んでも、自分の用途に落とし込めない人
- 開発と事業相談・生活相談の両方でAIを使う人
検証方法と課題
- スコア化ではなく、同じ課題を全構成に投げて出力そのものを読み比べる方式
- プログラミング系:TTL付きLRUキャッシュの実装、並列数制限処理、Job workerのバグ探し、ECの注文同期バッチのレビュー、EventEmitterの実装など
- 非プログラミング系:パン屋の売上低迷の原因分析、温泉旅館の集客改善、公務員の資産形成相談など
評価の観点
- 「正解できたか」だけでなく、指摘の深さ、誤検知の少なさ、優先順位の妥当性を見る
- 出力をそのまま実務に使えるか——つまり普段使いで効くかどうかを軸にした
注意点
- 評価はあくまで筆者の所感。AIの出力は生成のたびに揺れるため、同じ課題でも毎回同じ結果になるとは限らない
- 課題の種類やプロンプト次第で結果は変わり得る
- 「工数」は処理に割くリソース設定(低・中・高・特大)、「思考ON/OFF」は拡張思考の有無
- モデル表記は、OpusはすべてClaude Opus 4.8、SonnetはClaude Sonnet 4.6で統一
まず結論:迷ったらこれ
- 普段の実装:GPT-5.5 Thinking 拡張——読みやすく本番感があり、過剰設計しにくい。修正案まで落としやすい
- 軽い実装・説明:GPT-5.5 Thinking 通常——一番わかりやすく、最小実装がうまい。初手に向く
- 厳密なコードレビュー:Claude Opus 4.8 工数高・思考ON——本当にバグかを慎重に判定し、情報不足を切り分け、誤検知を避ける
- 高難度バグ探し・設計破綻の発見:Claude Opus 4.8 工数特大・思考ON——根本原因まで見て、個別バグを設計問題として統合し、不変条件まで考える
- 小規模事業・現場制約込みの相談:Claude Fable 5 工数高——やることを絞り、やらないことの判断がうまく、目標の現実性を見られる
- 施策をたくさん出したい:GPT-5.5 Thinking 拡張——実行メニューが豊富で具体策が多い
- 軽い一次チェック:Claude Sonnet 4.6 工数低・思考OFF——明らかな問題を低コストでざっくり拾える
比較した8構成の全体像
- GPT-5.5 Thinking 通常:読みやすい実務担当者
- GPT-5.5 Thinking 拡張:本番感覚のあるシニア実装者
- Claude Sonnet 4.6 工数低・思考OFF:軽量レビュー担当
- Claude Opus 4.8 工数中・思考OFF:簡潔な上級レビュアー
- Claude Opus 4.8 工数高・思考ON:慎重な査読者・設計レビュアー
- Claude Opus 4.8 工数特大・思考ON:テックリード・アーキテクト
- Claude Fable 5 工数高:現場を知る経営参謀
- Claude Fable 5 工数特大:設計を綺麗にしすぎる上級設計者
各モデルの詳細評価
GPT-5.5 Thinking 通常:読みやすい実務担当者
得意なこと
- プログラミング
- 最小実装と読みやすいコード
- 使用例つきの実装
- 軽めのバグ探し
- 初学者にもわかる説明
- プログラミング以外
- 具体的な行動案、数字や目安の提示
- 施策の提案、「まず何をするか」の整理
苦手なこと
- 深い条件分岐や、本番の細かい事故パターン
- 設計破綻の根本原因分析、厳密な仕様レビュー
- 優先順位の最終判断が少し揺れることがある
検証で見えた傾向
- コード生成はかなり読みやすい。ただし細かい堅牢性では拡張に負ける
- バグ探しでは主要論点は拾うが、「最優先3つ/5つ」の選定で少し迷うことがある
- 事業相談では、すぐ動ける施策に落とすのがうまい
- 原因分析では、構造より施策に早く進みやすい
向いている場面
- とりあえず実装したい
- 説明をわかりやすくしてほしい
- 軽くレビューしたい、行動計画がほしい
- 初手の相談相手にしたい
GPT-5.5 Thinking 拡張:本番感覚のあるシニア実装者
得意なこと
- プログラミング
- 本番寄りの実装と、過剰設計しない堅牢化
- 非同期処理の失敗ケース、状態遷移の破綻検出
- バグ修正の優先順位づけと、修正案への落とし込み
- プログラミング以外
- 具体施策の整理と実行計画、施策の幅出し
- 現実的で実務に落ちる改善案
苦手なこと
- 根本原因を大きな構造として統合すること
- 厳密な不変条件の設計
- 施策を極限まで絞ること、ライブラリの暗黙仕様の細部
検証で見えた傾向
- TTL付きLRUキャッシュでは、通常版より細部の作り込みが良かった
- 並列数制限では、reject後に新規タスクの開始を止めるなど実務的な配慮があった
- バグ探しでは状態遷移や再実行リスクを拾え、注文同期でも主要問題をかなり拾えた
- ただしカーソル同期の「連続成功したところまでしか進めない」という厳密な不変条件は、Claude Opus 4.8 工数特大の方が上だった
向いている場面
- 普段の実務開発、本番寄りのTypeScript実装
- バグ探し、コードレビュー、修正案作成
- 事業改善の具体策出し
- 守備範囲が広く、「普段の相棒」として最有力
おすすめの組み合わせ運用
- まずGPT-5.5 Thinking 拡張に実装させる
- Claude Opus 4.8 工数高または工数特大にレビューさせる
- 最後にまたGPT-5.5 Thinking 拡張に修正させる
Claude Sonnet 4.6 工数低・思考OFF:軽量レビュー担当
得意なこと
- プログラミング
- 明らかなバグ探し、軽いレビュー、一次チェック
- ざっくり問題点を拾うこと
- プログラミング以外
- 軽い相談や短い一般論、簡易チェック
苦手なこと
- 深い構造化、条件付き判断、本番の複雑な失敗ケース
- 根本原因分析、最終レビュー
検証で見えた傾向
- 非同期の待ち忘れ、finally不足、retry不備などは拾えた
- ただし指摘の粒度は粗め。同じ問題を少し重複して説明することがある
- 深い設計破綻までは見えにくい
向いている場面
- 軽い一次レビュー、明らかなミス探し
- 高工数モデルを使う前の下見
- コストを抑えてざっと確認したいとき
Claude Opus 4.8 工数中・思考OFF:簡潔な上級レビュアー
得意なこと
- プログラミング
- 短く本質を拾い、重い問題を上位に置くこと
- DB競合やretry不備などを見抜くこと
- プログラミング以外
- 短めの構造整理、ざっくりした本質把握
苦手なこと
- 丁寧な説明、細かい失敗パターンの網羅
- 初学者向けの解説
- 高工数設定ほどの前提分け
検証で見えた傾向
- 思考OFFでもかなり強い。ただし説明が短め
- finally不足などの危険性をやや軽く扱う場面があった
- 詳細レビューとしては工数高に劣る
向いている場面
- 長文はいらないが、浅いレビューも嫌というとき
- 上級者向けに本質だけ短く出してほしいとき
Claude Opus 4.8 工数高・思考ON:慎重な査読者・設計レビュアー
得意なこと
- プログラミング
- 本当にバグかどうかの判定、誤検知の回避
- 改善余地と必須修正の分類、情報不足の切り分け
- 条件付き判断、設計レビュー
- プログラミング以外
- 原因分析、前提整理、制約整理
- 因果関係の整理、問題の構造化
苦手なこと
- すぐ実装コードに落とすこと、具体施策を大量に出すこと
- 初学者向けに柔らかく説明すること
- 実務上早く潰したい問題を、慎重に後ろへ回してしまうことがある
検証で見えた傾向
- キャッシュのレビューでは、TTLなしを即「必須修正」とせず、データが可変かどうか次第と判断した
- 「単一プロセスなら安全、複数インスタンスなら危険」のような前提分けがうまい
- パン屋の売上低迷では「低迷=時系列変化」、Web障害では「急上昇=不連続事象」と捉えた
- 公務員の資産形成相談では、職業属性・流動性・iDeCo制約を整理した
向いている場面
- 厳密なコードレビュー、「本当にバグか」の判定
- 改善余地と必須修正を分けたいとき
- 原因分析、事業や資産形成の前提整理
Claude Opus 4.8 工数特大・思考ON:テックリード・アーキテクト
得意なこと
- プログラミング
- 高難度バグ探し、設計破綻の発見、根本原因分析
- 不変条件の整理、同期処理、分散・DB整合性、冪等性
- アーキテクチャレビュー
- プログラミング以外
- 事業構造の分析、収益構造の分解
- 表面的施策ではなく根本レバーを見ること、長期戦略の整理
苦手なこと
- 軽い実装、最小修正、すぐ使える小さいコード
- 現場で即動く粒度の出力、コストを抑えたい作業
検証で見えた傾向
- Job workerでは、個別バグを「非同期制御フローの破綻」として統合した
- 注文同期では「成功分のmax updatedAtまでカーソルを進めても危険」と見抜いた
- 「連続成功したプレフィックスまでしかウォーターマークを進められない」という指摘は、今回の高難度バグ探しで一番深かった
- 温泉旅館の相談では、広告不足ではなく、単価・直販・再訪・手数料構造を見た
向いている場面
- 複雑な本番障害のレビュー、アーキテクチャレビュー
- 同期バッチや分散処理の検証、設計破綻の発見
- 事業構造の深い分析
注意点
- 深いが重い。簡単な実装には過剰
- 大きな設計修正に寄りやすい
- 最終的に実装へ落とすなら、GPT-5.5 Thinking 拡張に戻すのがおすすめ
Claude Fable 5 工数高:現場を知る経営参謀
得意なこと
- プログラミング
- 設計判断の説明、過剰設計を避けること
- 重要なエッジケースや実務影響の重い問題を拾うこと
- 通知やユーザー影響など、現実の事故に敏感
- プログラミング以外
- 小規模事業の相談、現場制約込みの判断
- やることを絞り、やらないことを決めること
- 目標の現実性の判断、少人数・低予算の戦略
苦手なこと
- Claude Opus 4.8 工数特大ほどの深い構造分析
- GPT-5.5 Thinking 拡張ほどの実装・実行コスパ
- 施策を大量に出すブレスト、万能モデルとしての常用
検証で見えた傾向
- 温泉旅館の相談では、顧客リスト・直予約・単価設計・平日ターゲットに施策を絞った
- スタッフが少ない前提を重視し、SNS毎日運用・大規模改装・広告分散・値下げを切った
- 「1年で1.5倍は攻めた目標。現実的には1.2〜1.3倍かも」と目標の現実性に踏み込めた
- 注文同期では通知の冪等性を重く見た。EventEmitterではonce設計やsnapshotの説明がかなり良かった
向いている場面
- 店舗・旅館・飲食・個人事業など、小規模事業の経営相談
- 何をやらないか決めたいとき、施策を減らしたいとき
- 目標が現実的か見たいとき、限られた人員・予算で判断したいとき
注意点
- 深さではClaude Opus 4.8 工数特大に、実装コスパではGPT-5.5 Thinking 拡張に負ける
- 「現場制約で絞る」用途に特化して使うのが正解
Claude Fable 5 工数特大:設計を綺麗にしすぎる上級設計者
得意なこと
- 構造化、中心原因の特定
- 情報不足の整理、派生問題の整理
- 細かい論点の拾い上げ
- 非プログラミング領域は比較材料がまだ少ないが、おそらく構造化には強い(現場実行ならFable 5 工数高の方が扱いやすそう)
苦手なこと
- 暗黙仕様を守ること、標準的な期待挙動の維持
- 実務上の優先順位づけ
- そのまま使える実装、最小修正
検証で見えた傾向
- EventEmitterでは、同一listenerの重複登録を1件扱いにした。構造としては綺麗だが、普通に期待される挙動とはズレる
- 注文同期では、Invalid DateがlastSyncedAtに伝播する問題を拾った
- 情報不足の整理は良い。ただし通知の冪等性を最優先から外すなど、Fable 5 工数高より実務感が弱く見えた
向いている場面
- 設計案の比較、内部構造の整理
- 問題の構造化、情報不足の洗い出し
注意点
- 「高工数だから常に良い」わけではない
- 綺麗な設計と要件適合は別物。採用前に必ず仕様チェックが必要
用途別の使い分け
プログラミング
- 軽い実装:GPT-5.5 Thinking 通常
- 本番寄り実装:GPT-5.5 Thinking 拡張
- 軽いレビュー:GPT-5.5 Thinking 通常 / Claude Sonnet 4.6 工数低・思考OFF
- 本気のレビュー:GPT-5.5 Thinking 拡張 / Claude Opus 4.8 工数高・思考ON
- 高難度バグ探し:Claude Opus 4.8 工数特大・思考ON / GPT-5.5 Thinking 拡張 / Claude Fable 5 工数高
- 設計破綻の発見:Claude Opus 4.8 工数特大・思考ON
- 誤検知を避けるレビュー:Claude Opus 4.8 工数高・思考ON
- 修正コードに落とす:GPT-5.5 Thinking 拡張
非プログラミング
- 具体的な行動案:GPT-5.5 Thinking 通常 / 拡張
- 施策を多めに出す:GPT-5.5 Thinking 拡張
- 原因分析:Claude Opus 4.8 工数高・思考ON / 工数特大・思考ON
- 事業構造を深く見る:Claude Opus 4.8 工数特大・思考ON
- 小規模事業で現実的に絞る:Claude Fable 5 工数高
- やらないことを決める:Claude Fable 5 工数高
- 目標の現実性を見る:Claude Fable 5 工数高 / Claude Opus 4.8 工数特大・思考ON
- 資産形成やキャリアの実行案:GPT-5.5 Thinking 通常 / 拡張
- 資産形成やキャリアの前提整理:Claude Opus 4.8 工数高・思考ON
実務での組み合わせフロー
- 単体で使い続けるより、フェーズごとにモデルを切り替える方が効果的
- 高工数・思考ONの構成は深い代わりに重く、すべての工程に使うのは非効率
- 「一番賢い設定を常用する」が最適解にならない点は、今回の検証で繰り返し見えた傾向
開発で使う場合
- 実装する:GPT-5.5 Thinking 拡張
- レビューする:Claude Opus 4.8 工数高・思考ON
- 難しいバグだけ深掘りする:Claude Opus 4.8 工数特大・思考ON
- 修正案に落とす:GPT-5.5 Thinking 拡張
事業相談で使う場合
- 施策を広く出す:GPT-5.5 Thinking 拡張
- 構造を深く見る:Claude Opus 4.8 工数特大・思考ON
- やることを絞る:Claude Fable 5 工数高
- 実行計画にする:GPT-5.5 Thinking 拡張
各モデルの弱点まとめ
- GPT-5.5 Thinking 通常
- 深い条件分岐が甘い。本番事故パターンの拾い漏れがある
- 優先順位が揺れることがある
- 構造分析より実行策に寄る
- GPT-5.5 Thinking 拡張
- 根本原因の統合整理はOpus 4.8 工数特大に劣る
- 論点が多くなりがち。厳密な不変条件設計はやや弱い
- ライブラリの暗黙仕様はチェックが必要
- Claude Sonnet 4.6 工数低・思考OFF
- 粒度が粗く、深掘りが弱い
- 指摘が重複することがある。最終レビューには向かない
- Claude Opus 4.8 工数中・思考OFF
- 説明が短く、細かい失敗パターンを落とす
- 高工数ほどの前提分けはない。初学者にはやや不親切
- Claude Opus 4.8 工数高・思考ON
- 慎重すぎる。実務上早く潰したい問題を後ろに回すことがある
- 実装や行動への落とし込みはGPT拡張より弱く、抽象度が高い
- Claude Opus 4.8 工数特大・思考ON
- 重い。簡単な実装には過剰
- 大きな設計修正に寄りやすく、現場ですぐ動く粒度は弱い
- Claude Fable 5 工数高
- Opus 4.8 工数特大ほど深くなく、GPT拡張ほど実装・実行コスパが良いわけでもない
- 施策を大量には出さず、刺さる領域がやや狭い
- Claude Fable 5 工数特大
- 設計を綺麗にしすぎる。暗黙仕様を削るリスクがある
- 実務上重い問題を「要件次第」として下げることがあり、そのまま採用するには危ないことがある
まとめ:最終的な使い分け
率直な評価
- かなり正直に言うと、どのモデルも万能ではない
- Fable 5は深さではOpus 4.8 工数特大に、実装・実行コスパではGPT-5.5 Thinking 拡張に負ける
- ただし小規模事業で「やることを減らす」「現場で回る施策に絞る」「目標の現実性を見る」用途では、Claude Fable 5 工数高がかなり強い
- つまり、それぞれに明確な得意領域がある
使い分けは5つに集約
- 作る・直す:GPT-5.5 Thinking 拡張
- 深く疑う:Claude Opus 4.8 工数特大・思考ON
- 本当にバグか判定する:Claude Opus 4.8 工数高・思考ON
- 現場で何をやる/やらないを決める:Claude Fable 5 工数高
- 軽く相談する:GPT-5.5 Thinking 通常
ベンチマークとの付き合い方
- ベンチマークの順位は「難問を解く力」の序列としては参考になる
- ただし、普段使いの最適解をそのまま教えてくれるわけではない
- 実際、高工数の構成が暗黙仕様を崩したり、慎重なモデルが急ぎの問題を後ろに回したりと、賢さと使いやすさが一致しない場面が何度もあった
- モデルを1つに決めず、「実装→レビュー→深掘り→修正」のようにフェーズごとに切り替えるのが現時点での最適解
Nexforgeの主要記事ガイド
Nexforge記事ガイド
AI副業、プログラミング学習、開発環境、AIモデル比較、ブログ運営の記事を目的別にまとめています。
関連入口: AI副業ロードマップ / プログラミング・開発記事まとめ
AIモデルを仕事や副業で使いこなすために有料講座まで検討している場合は、先に必要性を切り分けると判断しやすくなります。AIスクールをおすすめしない人では、目的・作業時間・成果物の準備が整っているかを確認する観点を整理しています。
無料相談でAI講座や学習サポートの違いを確認する場合は、AIスクールの無料相談は何社受けるべき?も先に確認してください。AIモデルの使い分けを学びたい人ほど、質問対応、作れる成果物、仕事や副業への支援範囲、料金総額、返金条件を同じ質問で比べると判断しやすくなります。
AIツール選び・AI活用の関連記事
AIを触るだけで終わらせないために、ツール比較、学習の始め方、仕事や副業での使い方を近いカードから確認してください。
AIツールを選ぶ
モデル比較、ChatGPTの使い方、AI学習の始め方を先に整理します。
AIを仕事や副業に使う
副業の始め方、PCが苦手な人の使い方、仕事での現実的な取り入れ方を確認します。
サイト全体から探す
AI副業、開発学習、ブログ運営の記事を広く探したい時の戻り先です。
【2026年版】Amazonで買えるおすすめノートPCランキング!コスパ最強のモデルはこれだ

Amazon の PC をスコア化してみた
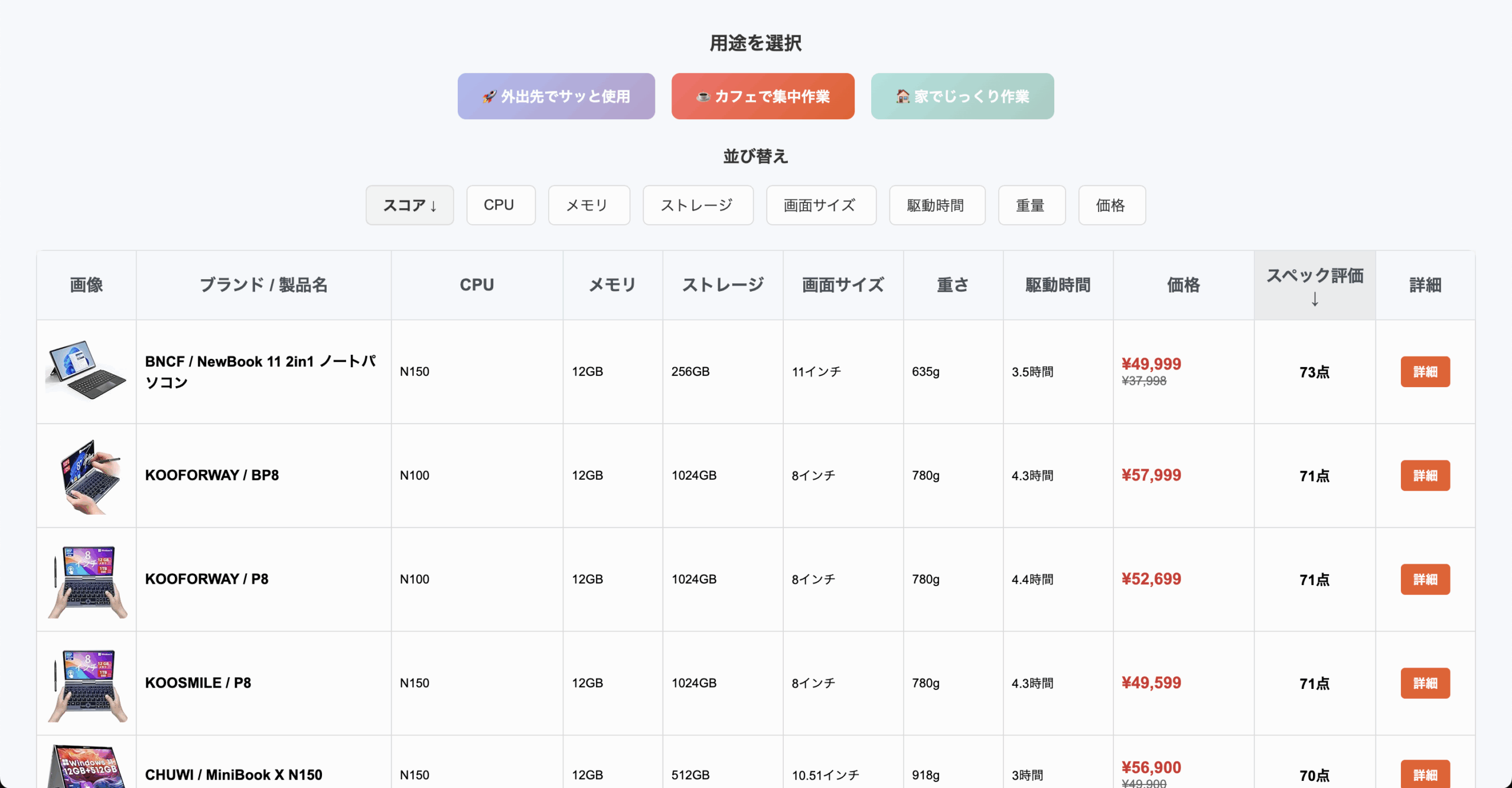
Amazonにある8〜14インチの小型WindowsタブレットやノートPCを、スペック別にスコア化して比較・ランキング。


コメント